Printed from www.flong.com
Contents © 2020 Golan Levin and Collaborators
Golan Levin and Collaborators
Projects
Sort by : Author | Date | Name | Type
- Installations
- Ghost Pole Propagator II
- Augmented Hand Series
- Eyeshine
- Re:FACE, Anchorage Version
- Merce's Isosurface
- Double-Taker (Snout)
- Opto-Isolator
- Eyecode
- Interstitial Fragment Processor
- Reface [Portrait Sequencer]
- Ghost Pole Propagator
- Footfalls
- Scrapple (Installation)
- The Manual Input Workstation
- Interactive Bar Tables
- Messa di Voce (Installation)
- Hidden Worlds of Noise and Voice
- Re:MARK
- Introspection Machine
- Audiovisual Environment Suite
- Dakadaka
- Rouen Revisited
- Performances
- Ursonography
- Scrapple (Performance)
- The Manual Input Sessions
- Messa di Voce (Performance)
- Dialtones (A Telesymphony)
- Scribble
- Net.Artworks
- Terrapattern
- Moon Drawings
- Free Universal Construction Kit
- QR Codes for Digital Nomads
- The Dumpster
- Axis
- JJ (Empathic Network Visualization)
- The Secret Lives of Numbers
- Alphabet Synthesis Machine
- Obzok
- Sketches
- Stria
- Dendron
- Slamps
- Banded Clock
- Floccus
- Stripe
- Meshy
- Directrix
- Yellowtail
- Streamer
- Blebs
- Self-Adherence (for Written Images)
- Poster design for Maeda lecture
- The Role of Relative Velocity
- Segmentation and Symptom
- Floccular Portraits
- Curatorial
- Mobile Art && Code
- ART AND CODE
- Code, Form, Space
- IEEE InfoVis 2008 Art Exhibition
- Solo exhibition at bitforms gallery
- IEEE InfoVis 2007 Art Exhibition
- Signal Operators
- Commercial / Industrial
- Motion Traces [A1 Corridor]
- Civic Exchange Prototype
- Amore Pacific Display
- Interactive Logographs
- Interval Projects
- Media Streams Icons
- Miscellaneous
- NeoLucida
- Rectified Flowers
- GML Experiments
- New Year Cards
- Admitulator
- Glharf (or Glarf)
- Finger Spies
Mouther
1995 | Golan Levin with Malcolm Slaney and Tom Ngo
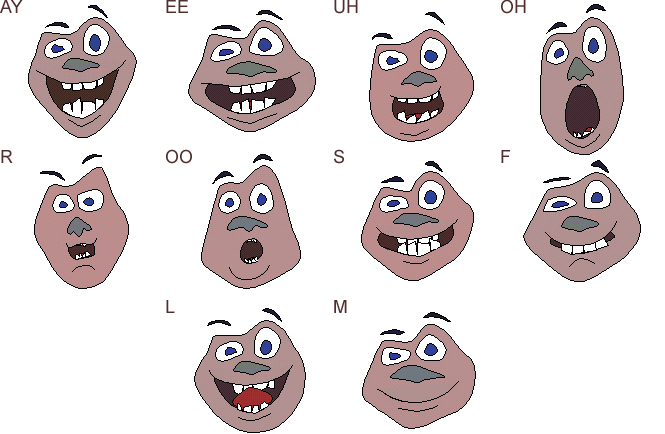
Mouther is a experimental prototype I helped develop at Interval Research, in which an animated cartoon face is lip-synched in real-time to the user's speech. I developed the prototype concept and artwork using Tom Ngo's in-house "Embedded Constraint Graphics" (ECG) animation engine, while Malcolm Slaney made Mouther possible by connecting these graphics to special speech-parsing technologies.
Mouther works by driving an embedded-constraint graphic with the output of a phoneme recognizer. This phoneme recognizer was built using mel-frequency cepstral coefficients (MFCC) as features and using maximum-likelihood selection based on Gaussian mixture models (GMMs) of each phoneme. Depending on the amount and diversity of training data, speaker-dependent or speaker-independent GMMs could be formed for each phoneme. To reduce the system's sensitivity to microphone and room acoustics, the MFCC's were filtered by RASTA (a widely accepted method for reducing the dependence of acoustic features on channel characteristics) prior to classification.
The result is a talking cartoon face whose animation is driven by the output of the classifier, and in which different mouth positions are displayed for the different phonemes that are spoken. While further work would be needed to increase the reliability of the classifier and the realism of the transitions between different visemes, the current result is amusing and could be sufficiently responsive for the quality-level needed in children's computer games.